Architektura RAG dla Dokumentów Prawnych
RAG sprawia, że analiza dokumentów jest praktyczna dla kancelarii prawnych. Jak działa, dlaczego jest lepsza od fine-tuningu i jak wygląda RAG z priorytetem prywatności.
Problem, Który RAG Rozwiązuje
Modele językowe są trenowane na ogromnych zbiorach danych i rozwijają imponującą wiedzę ogólną, ale nie mają wiedzy o Twoich konkretnych dokumentach. Zapytaj GPT-4 o umowę podpisaną w ubiegłym miesiącu — nie wie o niej nic. Wiedza modelu ma datę graniczną treningu i nigdy nie obejmowała Twoich plików.
Naiwne rozwiązanie — dostrajanie modelu na Twoich dokumentach (fine-tuning) — ma poważne problemy:
- Koszt: Dostrajanie dużych modeli wymaga znacznych zasobów obliczeniowych
- Przestarzałość: Nowe dokumenty wymagają ponownego treningu
- Ryzyko halucynacji: Dostrojone modele mogą “pamiętać” dane treningowe w zawodny sposób
- Prywatność: Twoje dokumenty muszą zostać przesłane do infrastruktury treningowej, której możesz nie kontrolować
- Brak cytowań: Dostrojone modele generują tekst, a nie odniesienia do dokumentów źródłowych
Retrieval-Augmented Generation (RAG) rozwiązuje wszystkie te problemy bez modyfikowania bazowego modelu.
Jak Działa RAG
RAG łączy dwa systemy: system wyszukiwania znajdującyi istotne fragmenty dokumentów oraz system generowania (model językowy) syntetyzujący te fragmenty w spójną odpowiedź.
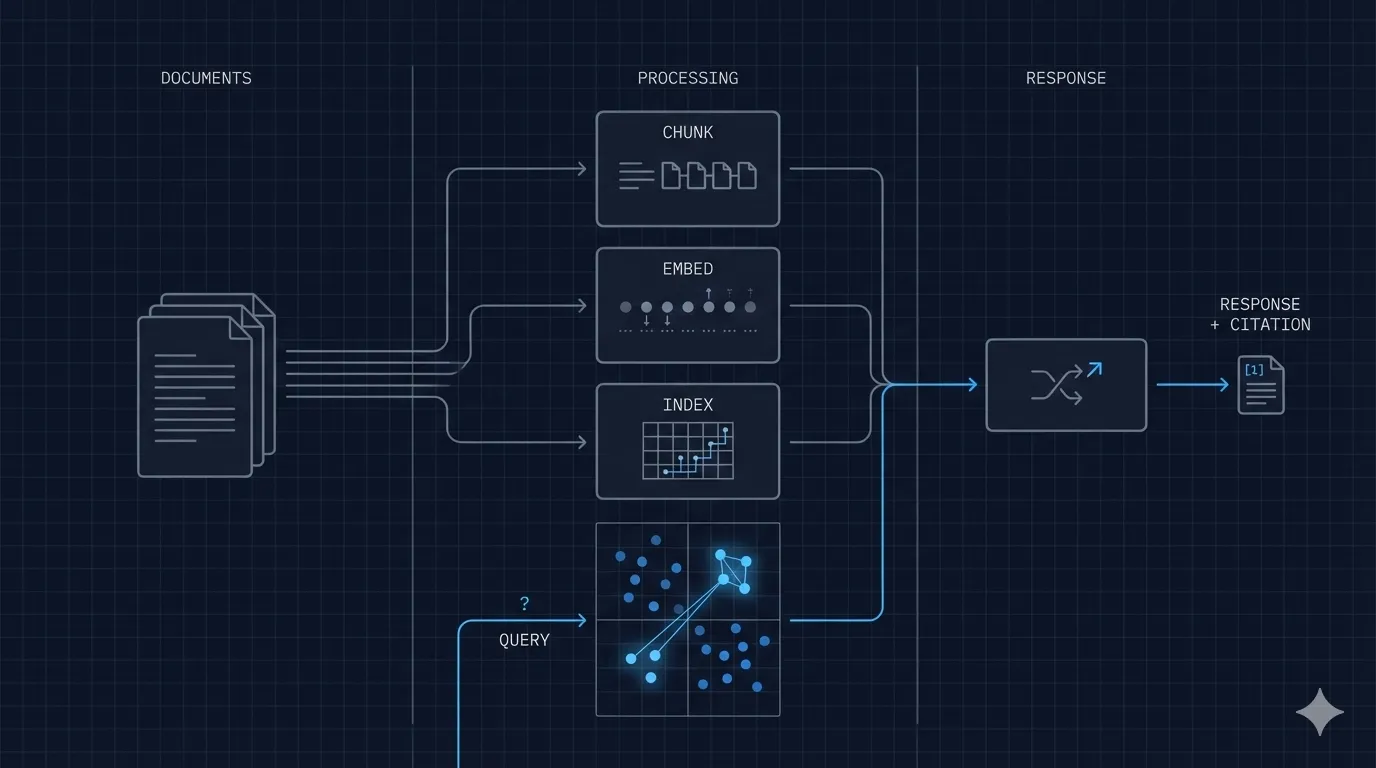
Krok 1: Indeksowanie
Dokumenty są przetwarzane w przeszukiwalny indeks:
- Każdy dokument jest dzielony na fragmenty (zazwyczaj 512–1024 tokeny z nakładaniem)
- Każdy fragment jest przekształcany w osadzenie wektorowe — numeryczną reprezentację jego znaczenia semantycznego — przy użyciu modelu osadzeń
- Wektory są przechowywane w bazie danych wektorów obok oryginalnych fragmentów tekstu
Model osadzeń jest kluczowy: konwertuje tekst na liczby w sposób zachowujący znaczenie. Semantycznie podobne fragmenty dają podobne wektory, niezależnie od dokładnego brzmienia. “Uchylenie tajemnicy adwokackiej” i “ujawnienie stronom trzecim może pozbawiać ochrony przywileju” będą miały podobne osadzenia, mimo że nie mają wspólnych słów.
Krok 2: Wyszukiwanie
Gdy użytkownik zadaje pytanie:
- Pytanie jest konwertowane na wektor przy użyciu tego samego modelu osadzeń
- Baza danych wektorów znajduje fragmenty, których wektory są najbardziej podobne do wektora pytania (wyszukiwanie najbliższego sąsiada)
- Pobierane są górne K fragmenty (zazwyczaj 3–10) wraz z odniesieniami do dokumentów źródłowych
To jest wyszukiwanie semantyczne: szukanie znaczenia, nie słów kluczowych.
Krok 3: Generowanie
Pobrane fragmenty są składane w okno kontekstowe i dostarczane do modelu językowego wraz z pytaniem użytkownika:
System: Jesteś asystentem analizy dokumentów. Odpowiadaj na pytania wyłącznie
na podstawie dostarczonego kontekstu. Zawsze cytuj dokument źródłowy i numer
strony dla każdego twierdzenia.
Kontekst:
[Fragment 1: Klauzula umowna o odpowiedzialności — Źródło: umowa_fuzji.pdf, s. 47]
[Fragment 2: Definicja "Istotnego Negatywnego Wpływu" — Źródło: umowa_fuzji.pdf, s. 12]
...
Użytkownik: Co uruchamia klauzulę o istotnym negatywnym wpływie?Model generuje odpowiedź opartą na pobranych fragmentach, a ponieważ instruujemy go do cytowania źródeł, każde twierdzenie w odpowiedzi odsyła do konkretnego dokumentu i lokalizacji.
Dlaczego To Działa Lepiej Niż Fine-Tuning
| Aspekt | Fine-Tuning | RAG |
|---|---|---|
| Nowe dokumenty | Wymaga ponownego treningu | Natychmiastowe (ponowne indeksowanie) |
| Cytowania | Nieobsługiwane | Natywne |
| Ryzyko halucynacji | Wyższe (model “pamięta”) | Niższe (zakorzenione w pobranym tekście) |
| Koszt aktualizacji | Wysoki | Niski |
| Wyjaśnialność | Czarna skrzynka | Identyfikowalne do źródła |
| Prywatność | Dokumenty w danych treningowych | Dokumenty tylko w indeksie wyszukiwania |
Wyzwanie Dokumentów Prawnych
Dokumenty prawne stawiają specyficzne wyzwania, z którymi ogólne implementacje RAG radzą sobie słabo:
Wyzwanie 1: Struktura Dokumentu
Dokumenty prawne mają hierarchiczną strukturę — sekcje, podsekcje, klauzule, załączniki — i odsyłacze (“patrz Sekcja 4.2(a)(iii)”). Naiwne dzielenie według liczby znaków rozbija logiczne jednostki i traci kontekst.
Dobry RAG prawniczy używa dzielenia uwzględniającego strukturę: podziału na granicach klauzul zamiast arbitralnej liczby znaków, zachowania nagłówków sekcji i utrzymania kontekstu nadrzędnego dla zagnieżdżonych klauzul.
Wyzwanie 2: Zeskanowane Dokumenty
Wiele dokumentów prawnych istnieje jako zeskanowane pliki PDF — umowy podpisane na papierze, pisma sądowe, starsze materiały sprawy. Wymagają one OCR (optycznego rozpoznawania znaków) przed ekstrakcją tekstu.
Standardowe OCR produkuje tekst, ale traci informacje o układzie — w której kolumnie pojawia się cyfra, gdzie są adnotacje, jak wygląda blok podpisu. Dla celów prawnych ma to znaczenie. Położenie klauzuli w umowie może wpływać na jej interpretację.
Podejście Tacitus wykorzystuje dwupakietowe OCR: ekstrakcję zarówno warstwy tekstu (do przetwarzania semantycznego) jak i warstwy wizualnej (zachowującej strukturę wizualną dokumentu do wyświetlania cytowań). Gdy system cytuje źródło, może pokazać dokładną lokalizację na oryginalnej stronie.
Wyzwanie 3: Rozumowanie Między Dokumentami
Sprawy prawne rzadko dotyczą jednego dokumentu. Analiza due diligence może wymagać rozumowania na podstawie setek umów jednocześnie: znajdowania wszystkich klauzul odszkodowawczych, porównywania oświadczeń i gwarancji, identyfikowania brakujących standardowych postanowień.
Wymaga to nie tylko wyszukiwania na poziomie dokumentu, ale syntezy między dokumentami: zdolności do pobierania i porównywania istotnych klauzul z wielu dokumentów w jednym zapytaniu. Baza danych wektorów musi obsługiwać jednocześnie filtrowanie (według typu dokumentu, daty, strony) i ranking (według trafności).
Wyzwanie 4: Poufność
Tu większość komercyjnych implementacji RAG zawodzi w przypadku zastosowań prawnych. Aby korzystać z chmurowej usługi RAG, Twoje dokumenty muszą być:
- Przesłane do infrastruktury dostawcy
- Indeksowane na serwerach dostawcy
- Przetwarzane przez modele osadzeń dostawcy
- Przechowywane w bazie danych wektorów dostawcy
Na każdym etapie Twoje uprzywilejowane dokumenty klienta są w kontakcie z infrastrukturą, której nie kontrolujesz. To samo ryzyko naruszenia tajemnicy zawodowej, które dotyczy ogólnie chmurowej AI, dotyczy również chmurowego RAG.
Architektura RAG z Priorytetem Prywatności
Implementacja Tacitus adresuje poufność na poziomie architektonicznym:
┌─────────────────────────────────────────┐
│ Tacitus Cortex (lokalnie) │
│ │
│ ┌──────────┐ ┌───────────────────┐ │
│ │ Przyjęcie│───▶│ Dwupakietowe OCR │ │
│ │ Dokumentów│ │ (tekst + wizual) │ │
│ └──────────┘ └────────┬──────────┘ │
│ │ │
│ ┌────────▼──────────┐ │
│ │ Silnik Podziału │ │
│ │ (uwzgl. strukturę)│ │
│ └────────┬──────────┘ │
│ │ │
│ ┌────────────▼──────────┐ │
│ │ Model Osadzeń │ │
│ │ (działa lokalnie) │ │
│ └────────────┬──────────┘ │
│ │ │
│ ┌────────────▼──────────┐ │
│ │ Baza Danych Qdrant │ │
│ │ (lokalnie) │ │
│ └────────────┬──────────┘ │
│ │ │
│ ┌──────────┐ ┌────────▼──────────┐ │
│ │Interfejs │───▶│ Lokalny LLM │ │
│ │Zapytań │ │ (Mistral/Llama) │ │
│ └──────────┘ └───────────────────┘ │
└─────────────────────────────────────────┘
Żadne dane nie opuszczają tej granicyKażdy komponent działa na lokalnym urządzeniu:
- Model osadzeń: Kwantyzowany transformer zdań działający na lokalnym GPU
- Baza danych wektorów: Qdrant, baza danych wektorów o otwartym kodzie źródłowym bez zależności od chmury
- Model językowy: Kwantyzowany LLM o otwartych wagach (zazwyczaj warianty Mistral lub Llama) działający na dedykowanym GPU
- Silnik cytowań: Mapuje wyjścia modelu z powrotem na lokalizacje dokumentów źródłowych
Brak wywołań API. Brak osadzeń chmurowych. Brak zewnętrznego wnioskowania modelu. Cały potok działa na sprzęcie pod Twoją fizyczną kontrolą.
Co To Oznacza w Praktyce
Dla kancelarii prawnej RAG z priorytetem prywatności oznacza:
- Przesłanie dokumentu = pozostaje lokalnie: Pliki są przetwarzane na urządzeniu i nigdy nie opuszczają Twojej sieci
- Zapytania = bez zewnętrznych wywołań API: Pytania trafiają do lokalnego modelu, nie do OpenAI czy Anthropic
- Odpowiedzi = ugruntowane i cytowane: Każda odpowiedź odwołuje się do konkretnego dokumentu i strony, która ją popiera
- Ścieżka audytu = lokalne dzienniki: Kompletny zapis tego, kto zapytał co i co zostało pobrane, przechowywany w Twoich systemach
AI działa jak bardzo oczytany współpracownik, który przeczytał wszystko w aktach Twojej sprawy i może natychmiast znaleźć odpowiednie fragmenty — ale który jest przez Ciebie zatrudniony, pracuje w Twoim biurze i nie może nikomu przekazać tego, co przeczytał.
Tacitus Cloud Bridge to najszybsza droga do produkcyjnego RAG prawniczego bez inwestycji sprzętowej. Poproś o wersję próbną, aby ocenić ją na swoim zbiorze dokumentów.