RAG Architecture for Legal Documents
Retrieval-Augmented Generation makes document intelligence practical for law firms. How it works, why it's better than fine-tuning, and what privacy-first RAG looks like.
The Problem RAG Solves
Language models are trained on vast datasets and develop impressive general knowledge, but they have no knowledge of your specific documents. Ask GPT-4 about a contract you signed last month, and it knows nothing about it. The model’s knowledge has a training cutoff and never included your files to begin with.
The naive solution — fine-tuning a model on your documents — has significant problems:
- Cost: Fine-tuning large models requires substantial compute
- Staleness: New documents require re-training
- Hallucination risk: Fine-tuned models can “remember” training data in unreliable ways
- Privacy: Your documents must be uploaded to a training infrastructure you may not control
- No citations: Fine-tuned models generate text, not references to source documents
Retrieval-Augmented Generation (RAG) solves all of these without modifying the underlying model.
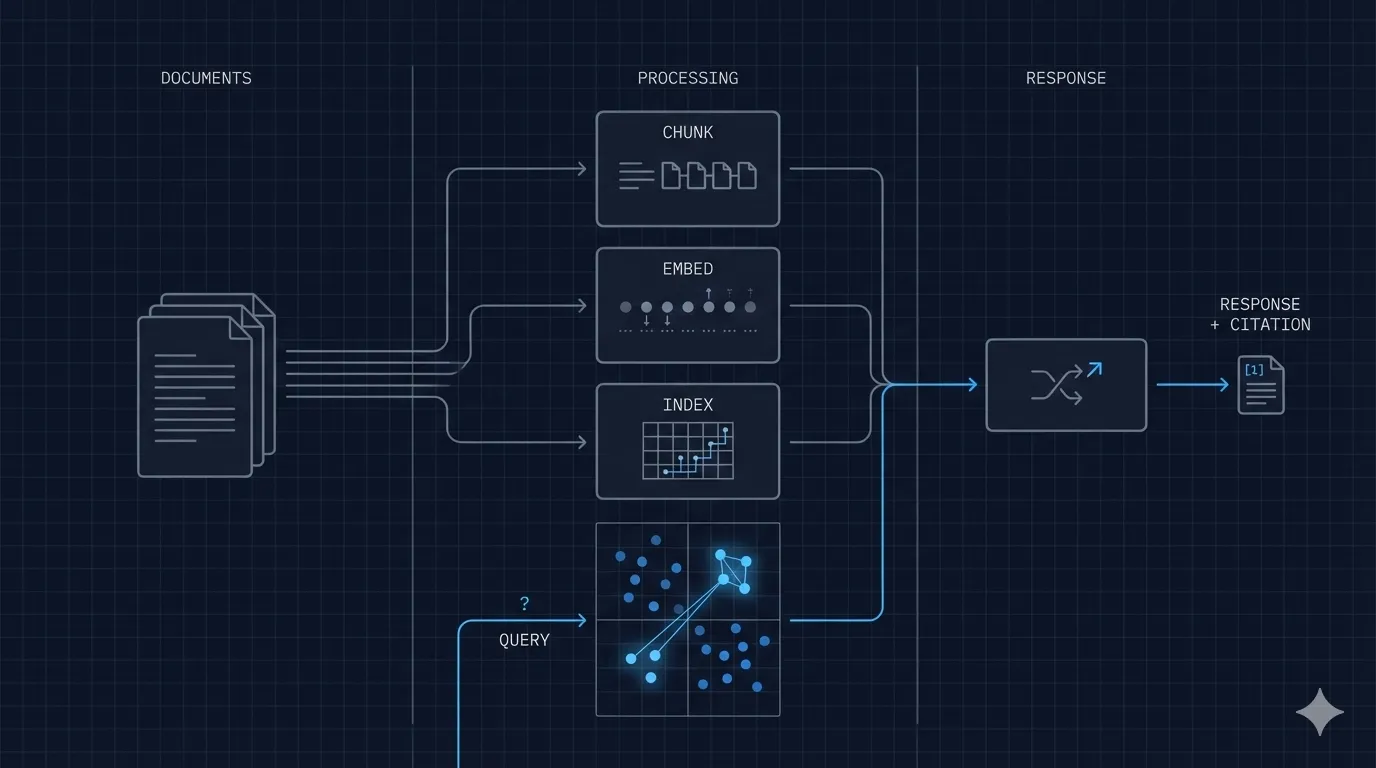
How RAG Works
RAG combines two systems: a retrieval system that finds relevant document passages, and a generation system (the language model) that synthesizes those passages into a coherent answer.
Step 1: Ingestion
Documents are processed into a searchable index:
- Each document is split into chunks (typically 512–1024 tokens with overlap)
- Each chunk is converted to a vector embedding — a numerical representation of its semantic meaning — using an embedding model
- The vectors are stored in a vector database alongside the original text chunks
The embedding model is the key: it converts text into numbers in a way that preserves meaning. Semantically similar passages produce similar vectors, regardless of exact wording. “Attorney-client privilege waiver” and “disclosure to third parties may void privilege” will have similar embeddings even though they share no words.
Step 2: Retrieval
When a user asks a question:
- The question is converted to a vector using the same embedding model
- The vector database finds the chunks whose vectors are most similar to the question vector (nearest-neighbor search)
- The top K chunks (typically 3–10) are retrieved along with their source document references
This is semantic search: finding meaning, not keywords.
Step 3: Generation
The retrieved chunks are assembled into a context window and provided to the language model along with the user’s question:
System: You are a document analysis assistant. Answer questions based only on the provided context.
Always cite the source document and page number for each claim.
Context:
[Chunk 1: Contract clause about liability — Source: merger_agreement.pdf, p. 47]
[Chunk 2: Definition of "Material Adverse Effect" — Source: merger_agreement.pdf, p. 12]
...
User: What triggers the material adverse effect clause?The model generates an answer grounded in the retrieved chunks, and because we instruct it to cite sources, every claim in the answer links back to a specific document and location.
Why This Works Better Than Fine-Tuning
| Aspect | Fine-Tuning | RAG |
|---|---|---|
| New documents | Requires re-training | Instant (re-ingest) |
| Citations | Not supported | Native |
| Hallucination risk | Higher (model “remembers”) | Lower (grounded in retrieved text) |
| Cost per update | High | Low |
| Explainability | Black box | Traceable to source |
| Privacy | Documents in training data | Documents in retrieval index only |
The Legal Document Challenge
Legal documents present specific challenges that general RAG implementations handle poorly:
Challenge 1: Document Structure
Legal documents have hierarchical structure — sections, subsections, clauses, exhibits — and cross-references (“see Section 4.2(a)(iii)”). Naive chunking by character count breaks logical units and loses context.
Good legal RAG uses structure-aware chunking: splitting at clause boundaries rather than arbitrary character counts, preserving section headers, and maintaining parent context for nested clauses.
Challenge 2: Scanned Documents
Many legal documents exist as scanned PDFs — contracts executed on paper, court filings, older case materials. These require OCR (Optical Character Recognition) before text extraction.
Standard OCR produces text but loses layout information — which column a figure appears in, where annotations are, what a signature block looks like. For legal purposes, this matters. A clause’s position in a contract can affect its interpretation.
The Tacitus approach uses dual-payload OCR: extracting both the text layer (for semantic processing) and a visual layer (preserving the document’s visual structure for citation display). When the system cites a source, it can show you the exact location on the original page.
Challenge 3: Cross-Document Reasoning
Legal matters rarely involve a single document. A due diligence exercise might require reasoning across hundreds of contracts simultaneously: finding all indemnification clauses, comparing representations and warranties, identifying missing standard provisions.
This requires not just document-level retrieval but cross-document synthesis: the ability to retrieve and compare relevant clauses from many documents in a single query. The vector database must be designed to support filtering (by document type, date, counterparty) and ranking (by relevance) simultaneously.
Challenge 4: Confidentiality
This is where most commercial RAG implementations fail for legal use cases. To use a cloud RAG service, your documents must be:
- Uploaded to the provider’s infrastructure
- Indexed on the provider’s servers
- Processed through the provider’s embedding models
- Stored in the provider’s vector database
At each step, your privileged client documents are in contact with infrastructure you don’t control. The same privilege risk that applies to cloud AI generally applies to cloud RAG specifically.
Privacy-First RAG Architecture
The Tacitus implementation addresses confidentiality at the architectural level:
┌─────────────────────────────────────────┐
│ Tacitus Cortex (on-premises) │
│ │
│ ┌──────────┐ ┌───────────────────┐ │
│ │ Document │───▶│ Dual-Payload OCR │ │
│ │ Intake │ │ (text + visual) │ │
│ └──────────┘ └────────┬──────────┘ │
│ │ │
│ ┌────────▼──────────┐ │
│ │ Chunking Engine │ │
│ │ (structure-aware) │ │
│ └────────┬──────────┘ │
│ │ │
│ ┌────────────▼──────────┐ │
│ │ Embedding Model │ │
│ │ (runs locally) │ │
│ └────────────┬──────────┘ │
│ │ │
│ ┌────────────▼──────────┐ │
│ │ Qdrant Vector DB │ │
│ │ (on-premises) │ │
│ └────────────┬──────────┘ │
│ │ │
│ ┌──────────┐ ┌────────▼──────────┐ │
│ │ Query │───▶│ Local LLM │ │
│ │ Interface│ │ (Mistral/Llama) │ │
│ └──────────┘ └───────────────────┘ │
└─────────────────────────────────────────┘
No data leaves this boundaryEvery component runs on the local appliance:
- Embedding model: A quantized sentence transformer running on the local GPU
- Vector database: Qdrant, an open-source vector database with no cloud dependencies
- Language model: A quantized open-weight LLM (typically Mistral or Llama variants) running on the dedicated GPU
- Citation engine: Maps model outputs back to source document locations
No API calls. No cloud embeddings. No external model inference. The entire pipeline runs on hardware under your physical control.
What This Means in Practice
For a law firm, privacy-first RAG means:
- Document upload = stays local: Files are processed on the appliance and never leave your network
- Queries = no external API calls: Questions go to the local model, not OpenAI or Anthropic
- Answers = grounded and cited: Every response references the specific document and page that supports it
- Audit trail = local logs: A complete record of who asked what and what was retrieved, stored on your systems
The AI operates like a very well-read associate who has read everything in your case files and can find the relevant passages instantly — but who is employed by you, works in your office, and cannot share anything they’ve read.
Getting Started
RAG is not a single product but an architecture. Implementing it well for legal documents requires careful attention to chunking strategy, embedding model selection, retrieval tuning, and prompt engineering. The privacy requirements add another layer of constraints that rule out most commercial offerings.
If you’re evaluating AI for document intelligence and want to understand what a privacy-first deployment looks like for your specific use case, a technical briefing is a good starting point.
The Tacitus Cloud Bridge is the fastest path to production-ready legal RAG without hardware investment. Request a trial to evaluate it against your document corpus.